ZFS Fileserver: LXC+Dataset vs VM+Zvol
Intro / recap #
Lately, I have been doing some benchmarking of my ZFS pools. I have been trying to learn the performance impact of different volblocksizes when running VMs on ZFS.
Selecting the wrong volblocksize can cause serious performance issues. Even though my VMs been trucking along just fine, I wanted to learn more about this and how to properly optimize it for production workloads.
You can see the results of round 1 and round 2 here.
VM vs LXC #
LXC: Originally, I ran my fileserver in a lightweight LXC container, using a storage-backed mount in Proxmox. I passed the mount directory (ext4) into the container and shared it via samba/nfs. Performance was great and it worked like a charm. The only major downside for me was that Proxmox Backup Server would then have to scan the entire disk in order to make the daily backups. LXC containers don't have a way to track changes to files, so even incremental backups still take way too long. I was using 5TB spinning disks at the time, and backups were taking about 3.5 hours at a minimum, even if there was nothing new to backup.
VM: Unlike LXCs, VMs do have a way to track which files have changed: dirty pages. As long as the VM is online and has not rebooted since the last backup, it will only scan and transfer new or modified files. This cut my backup times down from 3 hours to 3 minutes.
I have run my fileserver in a VM on a ZFS pool for about a year and a half now. It has worked great. I love the integration with Proxmox Backup Server, which allows me to very quickly backup, restore, and migrate the entire VM along with all of its data.
VMs running on ZFS pools in Proxmox introduce the volblocksize concept though, instead of using a recordsize. While a sub-optimal recordsize isn't that big of a deal, setting the wrong volblocksize can be much worse. That has been what I wanted to learn about through my testing.
Test results so far #
The benchmarks I've run so far have led to more questions than answers. The results are confusing. I'm not sure if my testing methodology is even sound for what I'm looking to learn. There is very little information online about volblocksize optimization and how to test it. I think the general idea is that you should avoid zvols like the plague unless you know exactly what size blocks will be written from your workload, and you are able to tailor each zvol to the specific data that it will contain. From my testing, speeds increase dramatically when pushing the volblocksize from the default 8k to as high as 64k. I don't have a heavy database or write/rewrite in place workload to really test the downside of that change, though.
So with that in mind, let's see if there's a way to avoid volblocksize completely, while retaining my favorite benefits of the VM.
Back to LXC #
So, I will complete the circle and go back to using a LXC. In order to avoid the super long backup times, I will switch up my backup process.
Proxmox Backup Server uses its own method to create incremental backups, which requires either scanning the entire disk or using dirty-pages for a VM. I will use zfs snapshots instead. Since my Proxmox Backup Server has a 48TB ZFS pool, I can just use zfs send/receive to back them up on the same pool but without the long scan and transfer times. Sending an incremental snapshot with zfs send should be nearly instant, no matter what the state of the container is.
Unfortunately, it's not possible to do ZFS snapshots inside the PBS gui yet. That's ok, though, since the commands should be pretty easy and scriptable. I will just have PBS continue to backup the container itself with the backup job in the gui.
There is one extra hoop to jump through in order to mount the zfs dataset inside the LXC, as well. The datasets need to be created and then added to the container manually, rather than creating a fixed-size dataset within the Proxmox gui.
Setup #
First, I created a new dataset (fileserver) on my zpool (fast):
zfs create fast/fileserverThen I configured permissions on the proxmox host. This is a great guide on how to configure permissions for this specific scenario. TLDR: Proxmox masks the true uid/gid inside containers for security reasons. In order to share files on the host from inside an unprivileged container, this workaround (or manual user-mapping) is necessary.
The uid/gid obfuscation works by adding 100,000 to whatever the container's value is. So uid 1000 in the container is uid 101000 on the host.
So I will make a fileserver users group with gid 110000 on the Proxmox host:
groupadd -g 110000 file_usersAnd then a user:
useradd files -u 101000 -g 110000 -m -s /bin/bashchown the dataset to the new user and group:
chown -R files:file_users /fast/fileserver/Then I created a new unprivileged ubuntu23 container.
Now start the container and add the user and group inside there:
groupadd -g 10000 file_users
useradd files -u 1000 -g 10000 -m -s /bin/bashShutdown the container.
Finally, we just have to add the mountpoint to the container configuration file. You can do this manually or just use pct set on the proxmox host:
pct set 109 -mp0 /fast/fileserver,mp=/mnt/filesNow run the container again.
Tadaaaaaa:
root@zfs-test:/mnt# ls
files
root@zfs-test:/mnt# Now before I get too excited and set up NFS and Samba, I'd like to just run the same benchmark I ran in round 1. Let's see how a raw dataset with 128k recordsize compares to all those volblocksizes.
Quick bench #
fio --name=random-write --rw=randrw --bs=4k --size=4g --numjobs=1 --iodepth=1 --runtime=60 --time_based --end_fsync=14k random read/write:
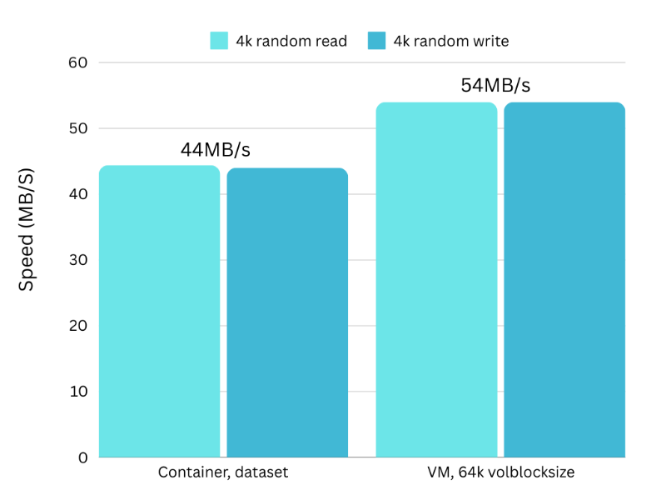
The VM is a bit faster than the container for tiny writes. What about 1M random?
1M random read/write:
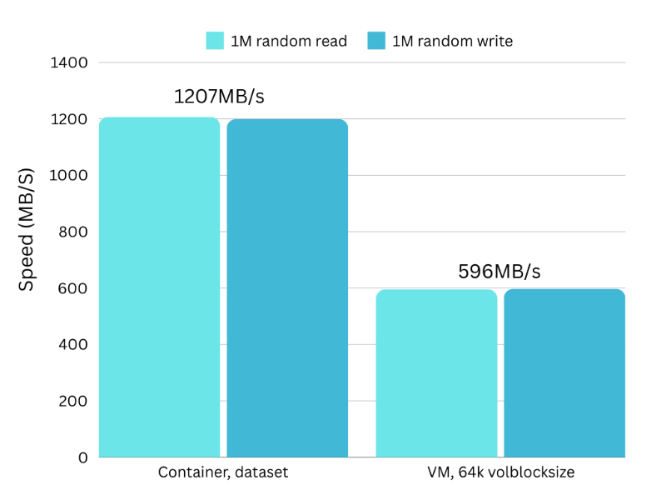
The container is 102% faster than the VM here. It transferred 72GB while the VM only transferred 36GB. Pretty cool!
samba time. #
Just installed the base ubuntu "samba" package. Made a basic smb.conf
[files]
path = /mnt/files
valid users = files
guest ok = no
writable = yes
browseable = yescreated user:
smbpasswd -a filesResults #
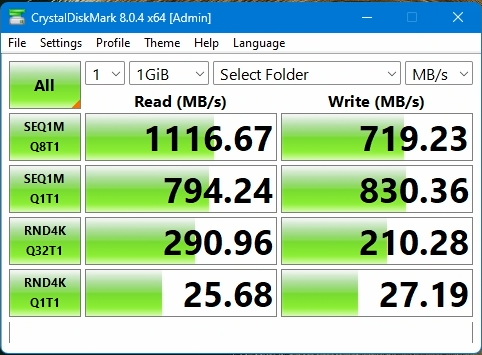
Ran crystaldiskmark on the network share again, from my windows11 PC connected via 10GbE.
In the container:
In the VM:
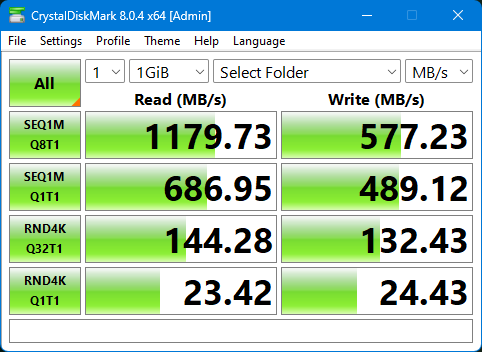
It's a lot faster!!
Nearly doubled the write performance when writing to the dataset directly rather than through a zvol.
Looking forward to learning how to automate snapshots and zfs send them to the Proxmox Backup Server! Will post a follow up.
Happy homelabbing!
- Previous: Thinkpad Backup Script
- Next: ZFS Fileserver: Automated snapshots