ZFS Volblocksize for VM Workloads
I store all of my VMs on ZFS pools. On Proxmox, VMs stored on ZFS pools will use zvols by default, rather than a disk file in a dataset. Proxmox zvols use a default volblocksize of 8k. What the heck is a zvol, and what is the impact on storage performance?
Zvols present a virtual block device to the VM, like a physical disk. It sounds pretty cool, but it comes with some caveats. Zvols use a volblocksize rather than a recordsize or a block size. Selecting the wrong volblocksize for your workload can result in extreme write amplification, increased drive wear, and terrible performance.
Volblocksize represents the minimum amount of data that can be written to a zvol. This is the opposite of recordsize, which refers to the maximum. Writing a 1kb file to a zpool with a recordsize of 128k is no problem -- ZFS will simply write 1k. The same 1k write on a zvol with volblocksize of 128k will cause 128k of data to be written. That's a write amplification of 128x. No bueno!
A similar situation occurs in reverse. You have a 128k volblocksize and you need to read 1k. ZFS must read the whole 128k block to return your 1k data. This can greatly increase latency and reduce IOPs.
It gets even worse if you're calculating parity -- arrays with certain drive configurations can lose 50% or more of their total usable space to metadata when block size is set too low. Look for posts discussing "padding overhead" or posts like this for more info.
I was hoping that the perfect volblocksize would be just a google search away... but it looks like it's gonna be more complicated than that! The volblocksize should precisely match the workload, 16k for databases which perform 16k writes, for example. I'm not sure exactly what that would be for my typical usage. So, my goal here is to just to learn what I can about how ZFS interacts with zvols, starting with some simple tests.
Testing Methodology - Round 1 #
I'll be using a striped mirror containing 4x 12TB drives. The underlying pool has ashift=12, compression=LZ4, recordsize=128k. I am testing inside a Debian VM with ext4 filesystem, 4k blocks, cache=none.
To test each volblocksize, I am simply moving the virtual disk off of the pool, resetting the volblocksize, and then moving the virtual disk back to the pool. (The data needs to be written again in order for the new volblocksize to take effect.)
For round one, I would like to find the extremes -- just to get some idea of the relationship between these values.
First, I used fio to test random writes of 4k and 1M blocks at queue depth 1. I ran both tests on volblocksizes 8k, 16k, 32k, and 64k. sync=disabled
fio --name=random-write --ioengine=posixaio --rw=randwrite --bs=1M --size=4g --numjobs=1 --iodepth=1 --runtime=60 --time_based --end_fsync=14k random writes: #
| Volblocksize | Block Size | IOPS | Bandwidth (MiB/s) | Average Latency (μs) | 99th Percentile Latency (μs) | Disk Utilization (%) |
|---|---|---|---|---|---|---|
| 8K | 4K | 15.7k | 61.2 | 41.74 | 99 | 86.15 |
| 16K | 4K | 18.1k | 70.8 | 32.89 | 93 | 78.41 |
| 32K | 4K | 19.7k | 76.8 | 33.55 | 105 | 79.44 |
| 64K | 4K | 25.1k | 97.9 | 35.81 | 126 | 55.38 |
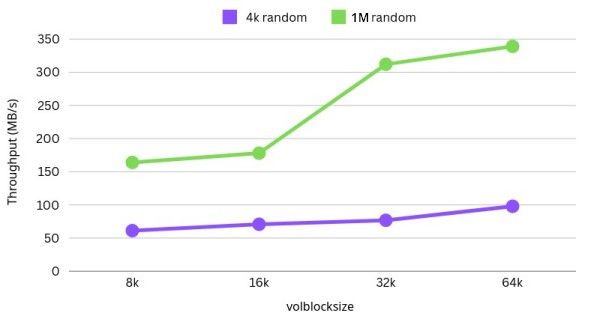
These results were surprising to me! Switching from 8k to 64k volblocksize, we see a 60% increase in throughput and a huge drop in iowait. There is a 60% increase in IOPs, as well.
I will have to run some more detailed tests here, but I suspect these huge gains may come with huge penalties in other areas. Namely, random reads that miss the ARC, or writes that require read/modify/write. Will have to figure out how to test that later.
1M random writes: #
| Volblocksize | Block Size | IOPS | Bandwidth (MiB/s) | Average Latency (μs) | 99th Percentile Latency (μs) | Disk Utilization (%) |
|---|---|---|---|---|---|---|
| 8K | 1M | 163 | 164 | 3136.59 | 217056 | 93.79 |
| 16K | 1M | 177 | 178 | 3638.31 | 125305 | 90.54 |
| 32K | 1M | 311 | 312 | 2207.24 | 143655 | 89.67 |
| 64K | 1M | 338 | 339 | 1933.32 | 43779 | 93.11 |
Same story here! 106% increase in random write speed switching from 8k volblocksize to 64k. 107% increase in IOPs. Much larger reduction in disk latency here than in the 4k tests.
I would bet we get the same trade-off here, issues with small random reads and modifying files in place. Someone give me a trail of breadcrumbs for how to test that!
Looking forward to round 2. Next time, I'd like to find a way to see how much amplification is going on here, as well as how badly this is affecting reads outside of ARC.
Would love some feedback on my methodology and some pointers! More fun to learn with friends. brianm88 @ gmail.com or /dev/goat on Steam.
Thanks for reading. Happy homelabbing!
- Previous: Building a better backup server
- Next: bash history